32-Prisma的全部schema语法
这节我们来学习下 Prisma 的 schema 文件的全部语法。
初始化
先创建个新项目:
mkdir prisma-schema
cd prisma-schema
npm init -y
全局安装 prisma:npm install -g prisma
然后进入项目,执行 init 命令:prisma init
生成了 .env 和 schema 文件:
然后改下 .env 文件的数据库连接信息:
DATABASE_URL="mysql://root:guang@localhost:3306/prisma_test"
改一下 db 的 provider 为 mysql,并且添加一个 model
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "mysql"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
}
然后执行 generate 命令:prisma generate
会在 node_modules/@prisma/client 下生成客户端代码:
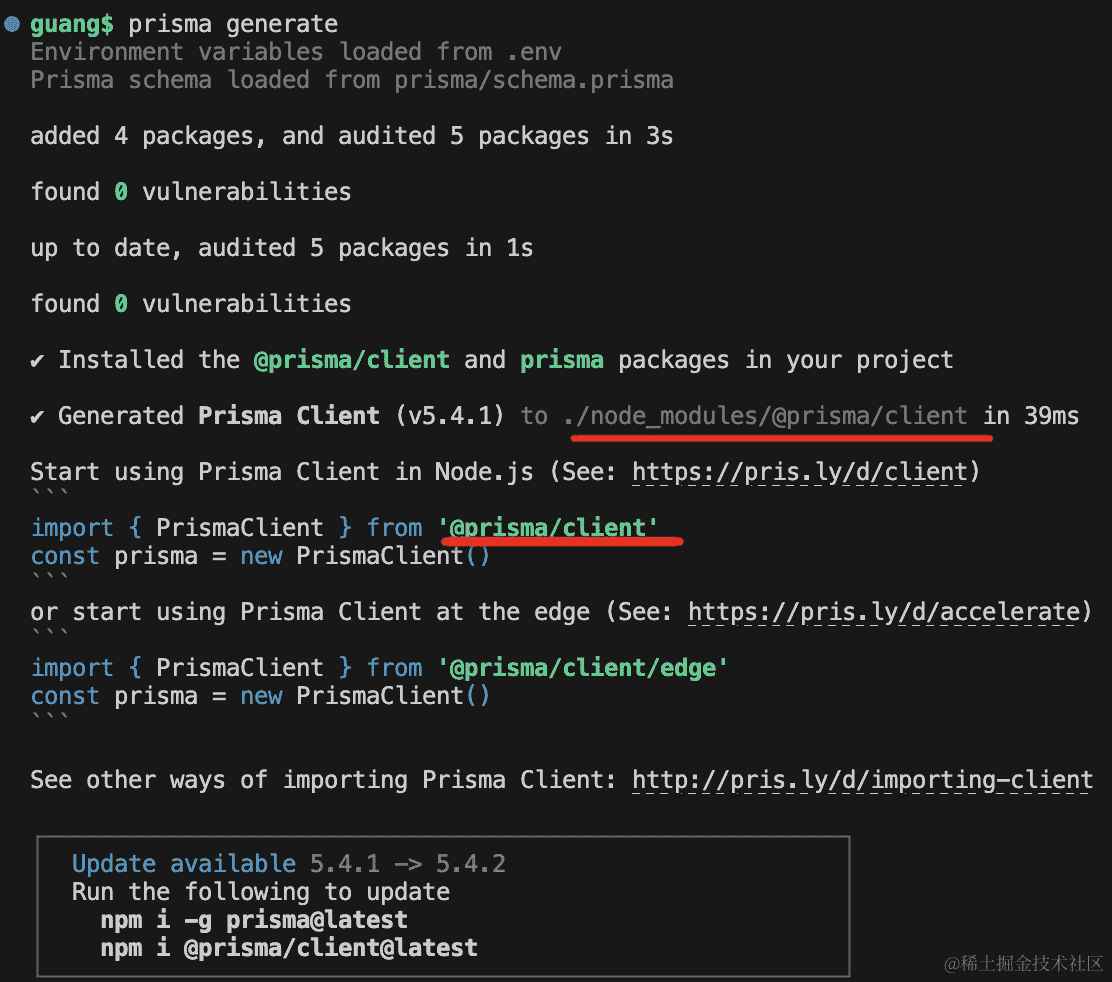
output
这个生成位置是可以改的:
 在 generator 指定 output 的位置即可:
在 generator 指定 output 的位置即可:
generator client {
provider = "prisma-client-js"
output = "../generated/client"
}
然后再次 generate:prisma generate
这时候就是在根目录生成的代码:

generator
此外,generator 除了可以生成 client 代码外,还可以生成别的东西。
在文档里可以看到有很多社区的 generator:

我们试一下这个 json 和 docs 的 generator:
npm install --save-dev prisma-docs-generator
npm install --save-dev prisma-json-schema-generator
先安装相关的包。
然后在 schema 文件里配置 3 个 generator:

generator client {
provider = "prisma-client-js"
output = "../generated/client"
}
generator docs {
provider = "node node_modules/prisma-docs-generator"
output = "../generated/docs"
}
generator json {
provider = "prisma-json-schema-generator"
output = "../generated/json"
}
把 generated 目录删掉,重新生成:npx prisma generate
注意,这里要用 npx 执行,因为如果是执行全局命令,会找不到项目目录下安装的 generator。
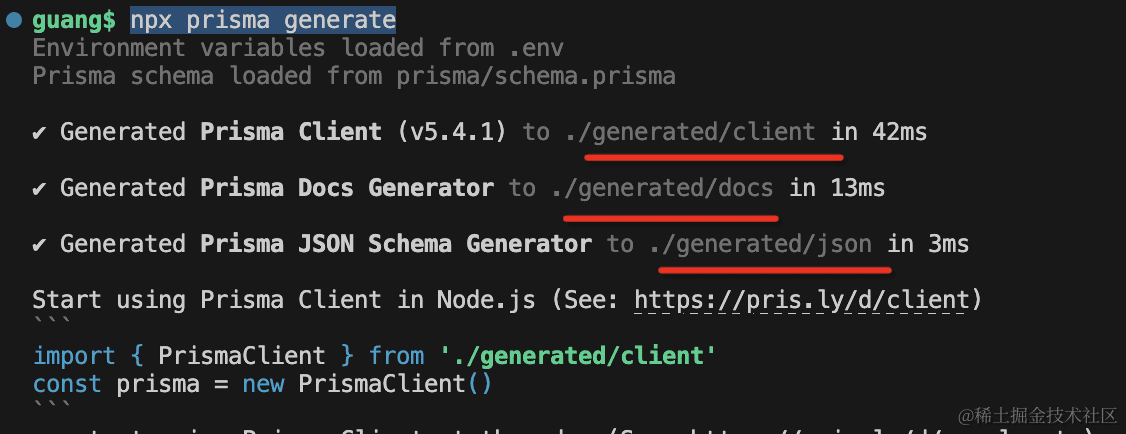
提示三个 generator 的产物都输出到了对应目录。
json schema 的 generator 会把 schema 文件转为 json 版:
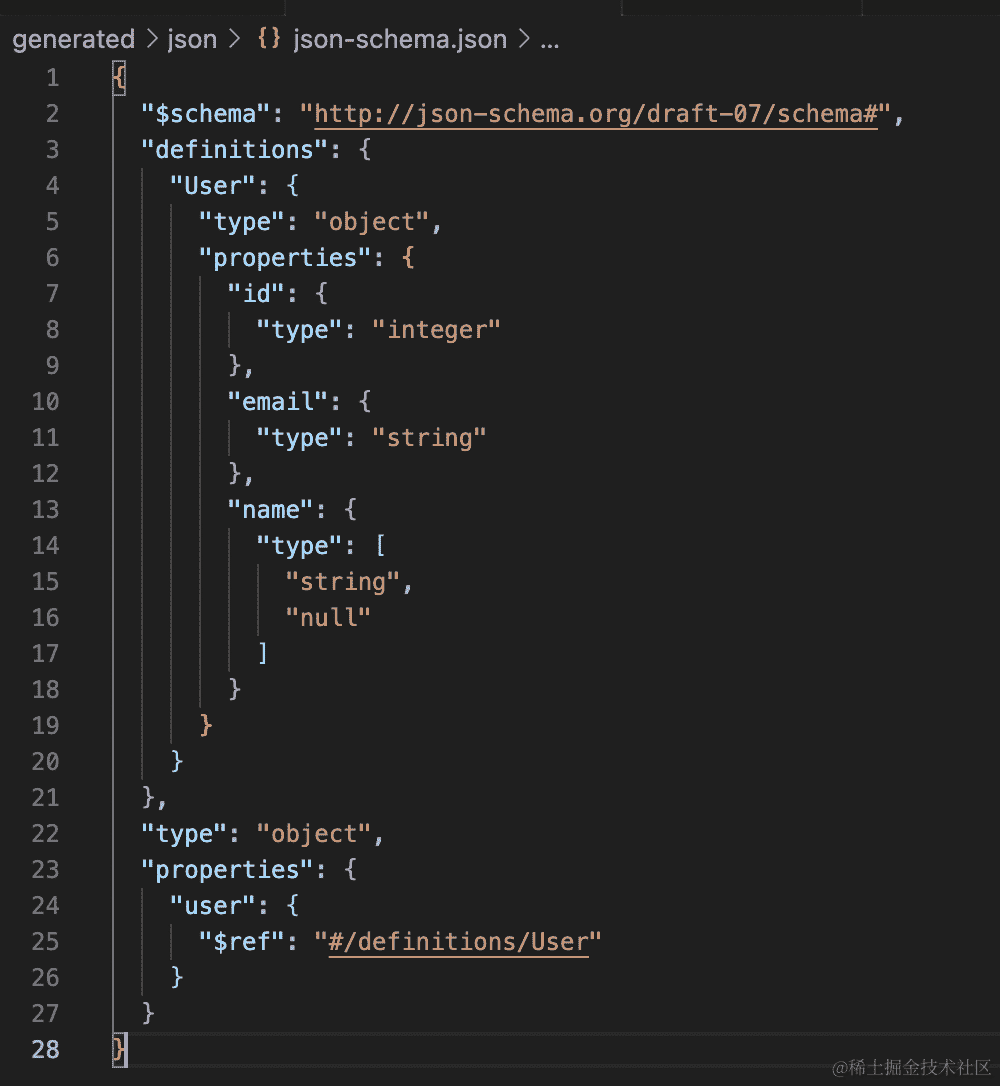
而 docs 则是会生成文档。
我们跑起来看看:
npx http-server ./generated/docs
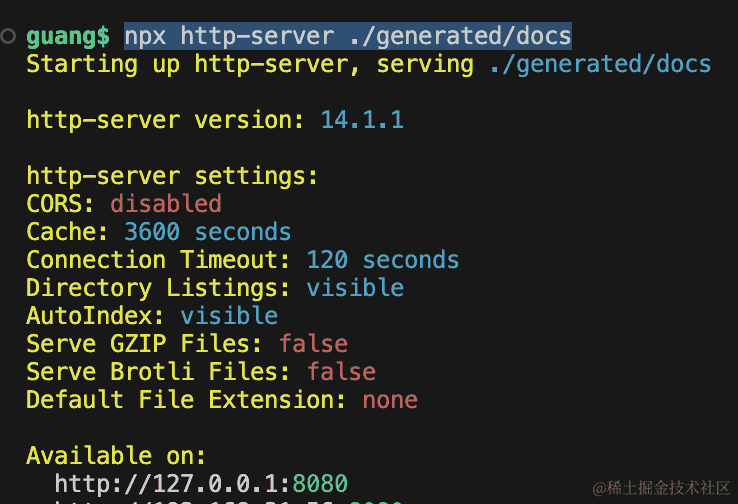
文档里会列出 model 的所有字段:

还有它的所有 CRUD 方法,每个方法的参数的类型等:

当你想做 crud 的时候,查下这个生成的文档,特别方便。
datasource
datasource 部分是配置数据库连接信息的。

provider 里指定连接的数据库的类型。
url
url 部分是连接的 url,也就是这个

在 schema 文件里可以用这种方式读取某个 env 的变量:

model
接下来是 model 部分。
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
}
这部分很容易看懂,第一列是字段名,第二列是类型,第三列是一些其他信息。
首先重置一下:prisma migrate reset
我们用 migrate 命令生成 sql:prisma migrate dev --name aaa
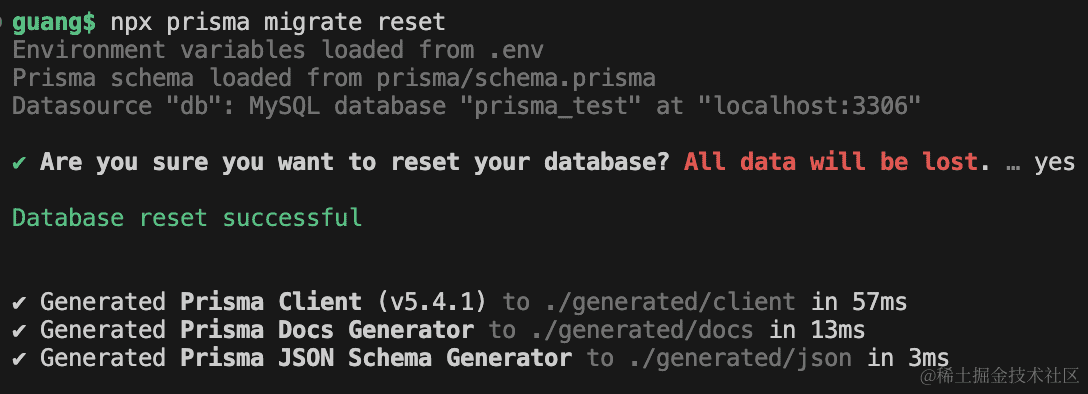
然后创建一个 aaa 的迁移:

它会创建对应的 sql 文件并执行:

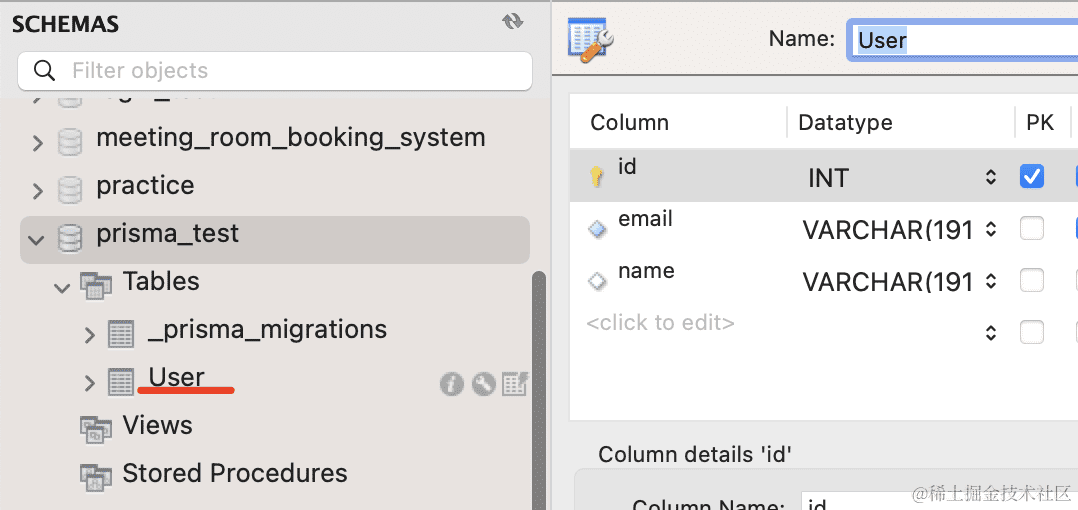
可以看到 model 的声明和生成的 sql 的对应关系:
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
}
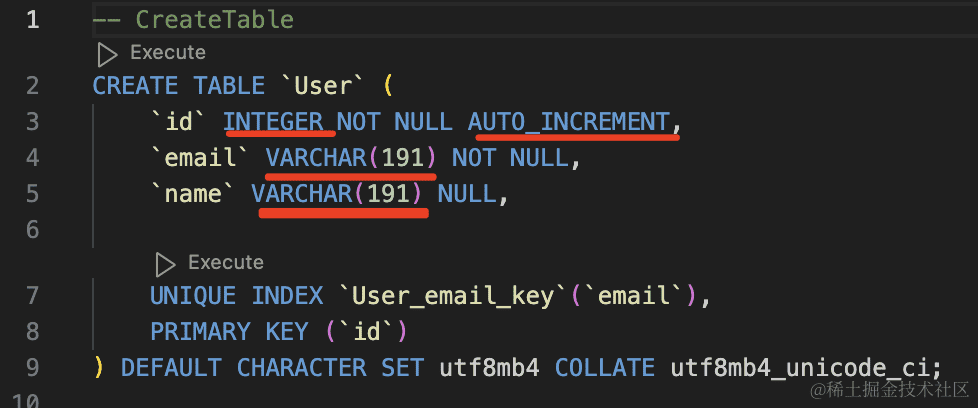
String 默认是 VARCHAR(191)
@id 会创建主键约束,@default 是默认值,而 autoincrement 是自增。
@unique 会创建唯一约束。

我们再创建一个 model
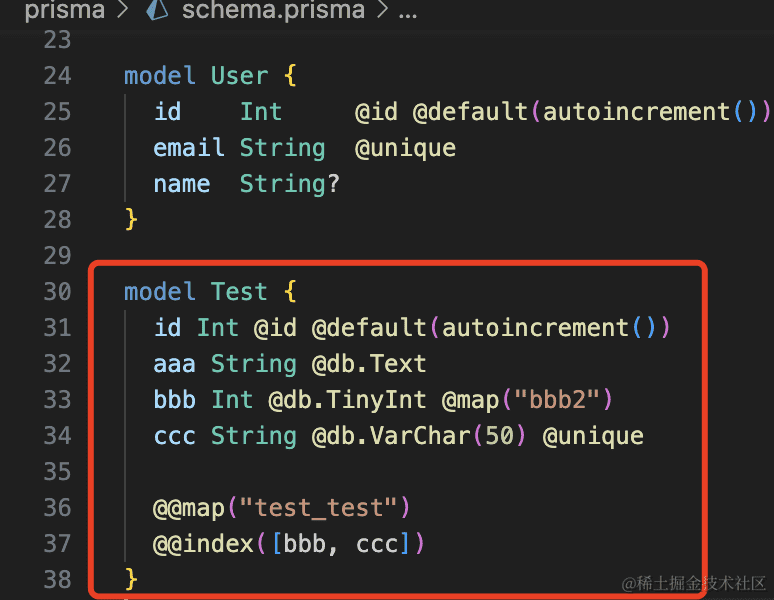
model Test {
id Int @id @default(autoincrement())
aaa String @db.Text
bbb Int @db.TinyInt @map("bbb2")
ccc String @db.VarChar(50) @unique
@@map("test_test")
@@index([bbb, ccc])
}
这是 @db.xxx 可以指定具体的 mysql 的数据类型,有括号的是可以填入参数的,比如 VARCHAR 可以指定长度:


@map 是给字段指定另一个名字,@@map 是给表指定另一个名字。
而 @@index 则是创建一个索引,这里创建了 bbb、ccc 的联合索引。
索引就像书的目录一样,可以加快 sql 查询速度,sql 优化的时候我们经常会把高频查询的字段创建索引。
我们测试下:
npx prisma migrate dev --name bbb
创建 bbb 的数据库迁移。
 生成的 sql 如下:
生成的 sql 如下:
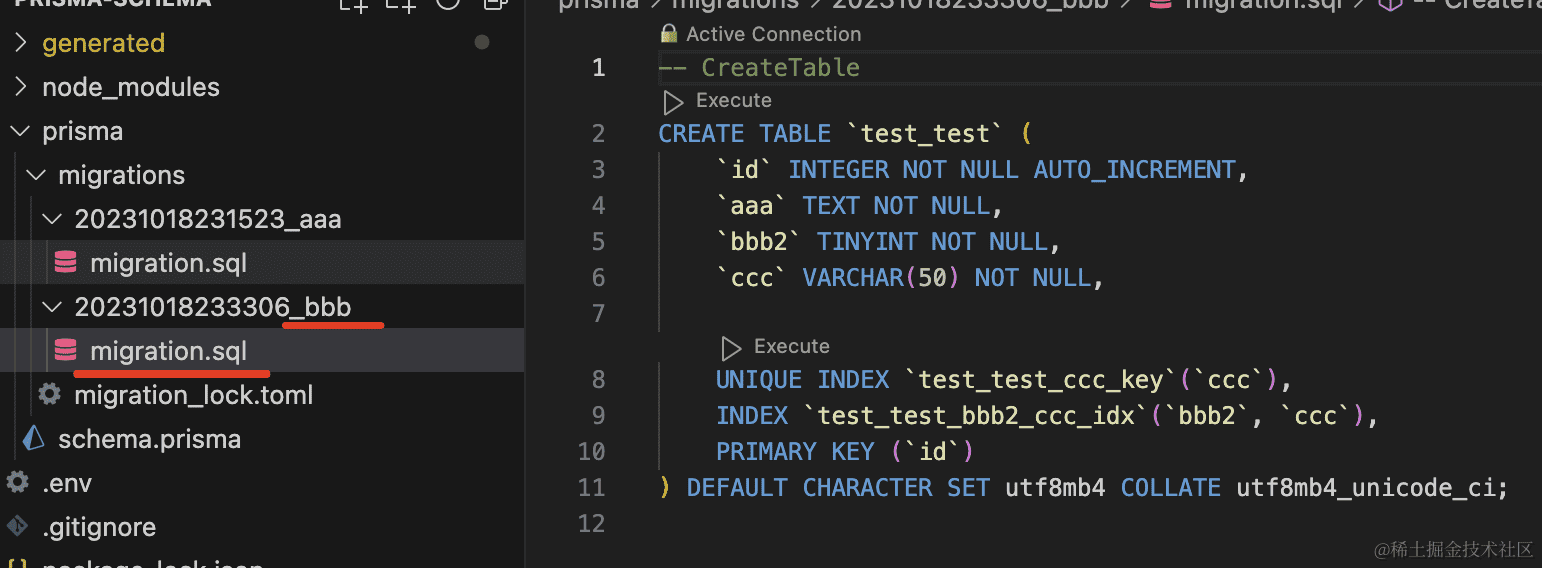
对比下 model 语法和生成的 sql:
model Test {
id Int @id @default(autoincrement())
aaa String @db.Text
bbb Int @db.TinyInt @map("bbb2")
ccc String @db.VarChar(50) @unique
@@map("test_test")
@@index([bbb, ccc])
}
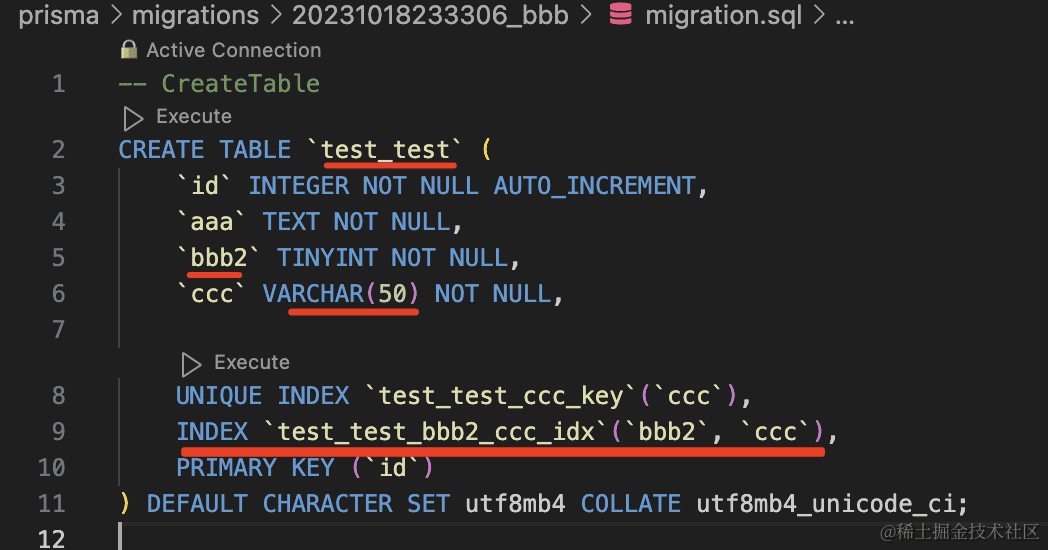
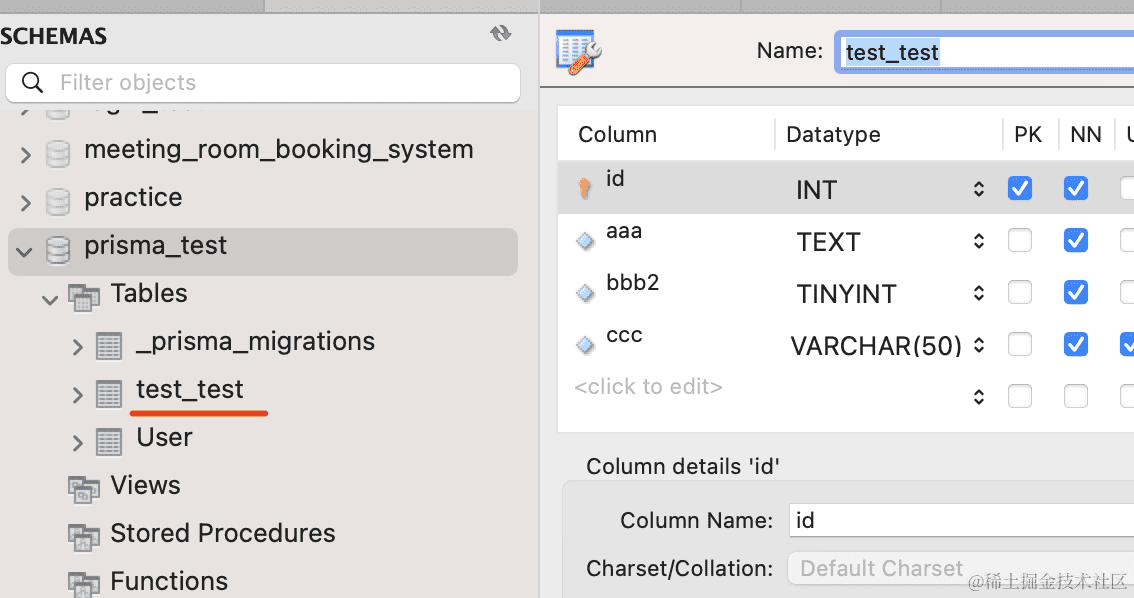
可以看到 @db.xxx、@map、@@map、@@index 都生效了
在 mysql workbench 里也可以看到这个表:
那表和表之间的一对多、多对多关系呢?
我们再添加几个 model:

model Department {
id Int @id @default(autoincrement())
name String @db.VarChar(20)
createTime DateTime @default(now())
updateTime DateTime @updatedAt
employees Employee[]
}
model Employee {
id Int @id @default(autoincrement())
name String @db.VarChar(20)
phone String @db.VarChar(30)
deaprtmentId Int
department Department @relation(fields: [deaprtmentId], references: [id])
}
这里用到了几个新语法:
创建时间我们使用 @default(now()) 的方式指定,这样插入数据的时候会自动填入当前时间。
更新时间使用 @updatedAt,会自动设置当前时间。
员工和部门是多对一关系,在员工那一侧添加一个 departmentId 的列,然后通过 @relation 声明 deaprtmentId 的列引用 department 的 id 列。
测试下:
npx prisma migrate dev --name ccc
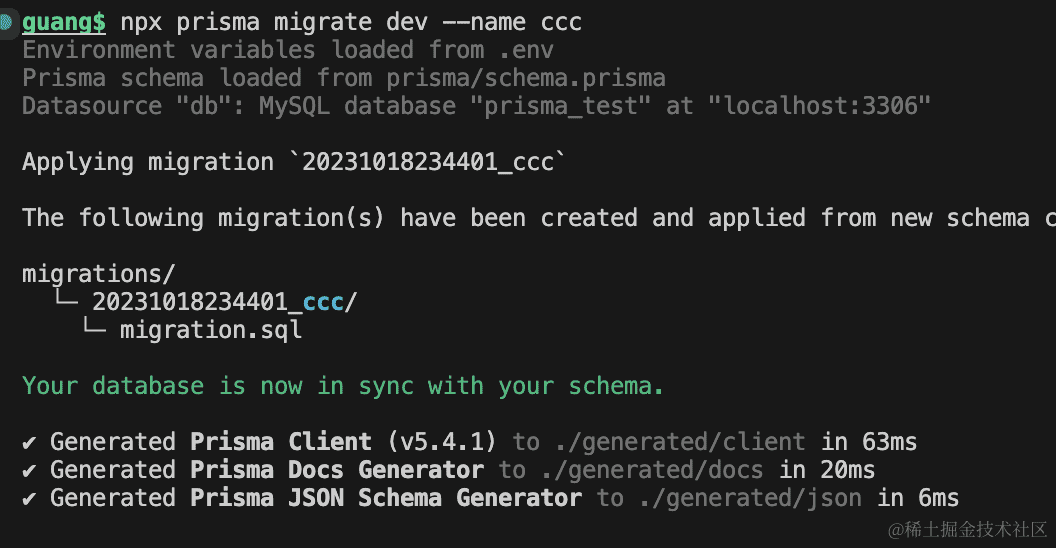
可以看到,生成的 sql 是符合预期的:
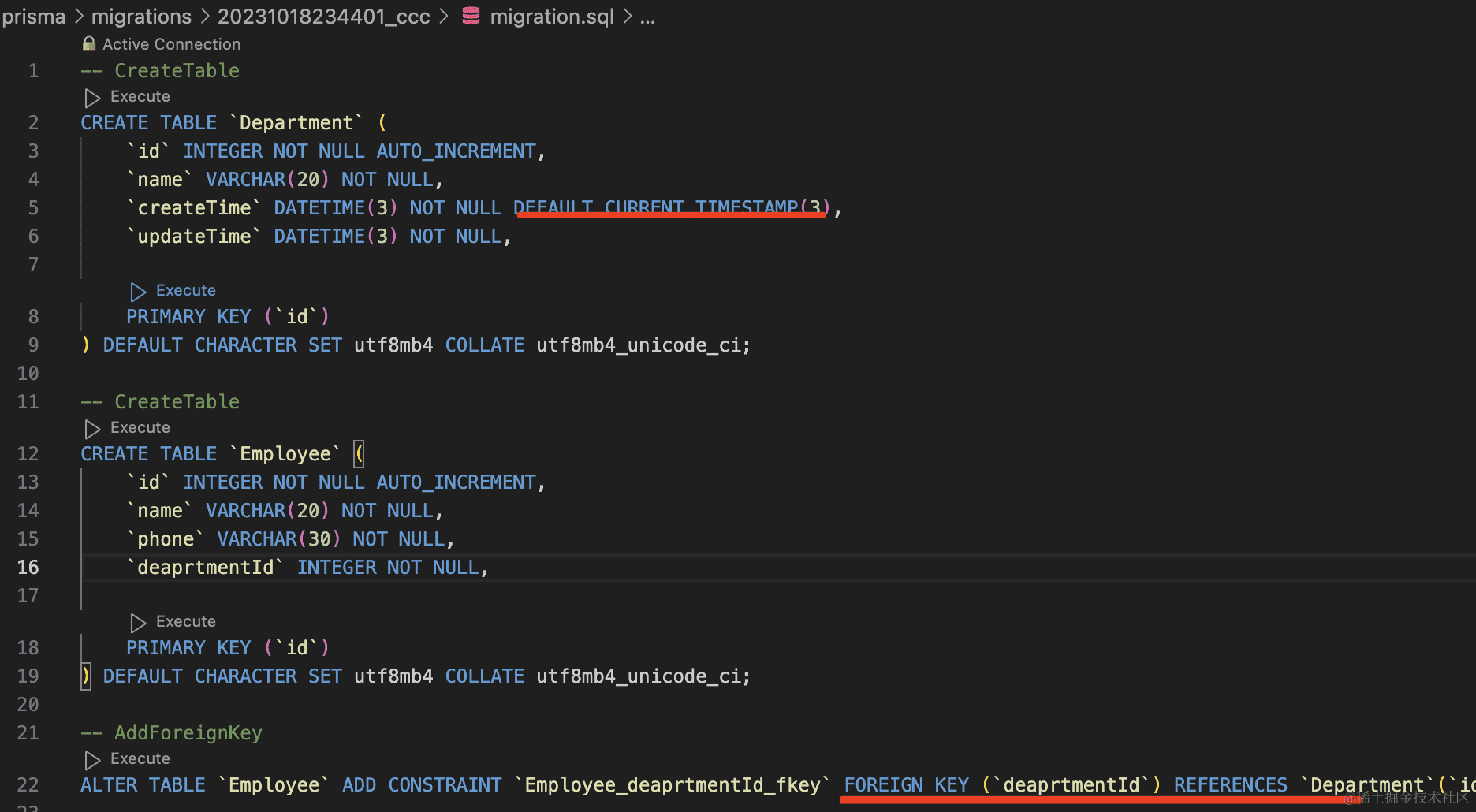
并且在数据库里可以看到创建了对应的外键:

然后是多对多:

model Post {
id Int @id @default(autoincrement())
title String
content String?
published Boolean @default(false)
tags TagOnPosts[]
}
model Tag {
id Int @id @default(autoincrement())
name String
posts TagOnPosts[]
}
model TagOnPosts {
post Post @relation(fields: [postId], references: [id])
postId Int
tag Tag @relation(fields: [tagId], references: [id])
tagId Int
@@id([postId, tagId])
}
有 sql 的基础很容易看懂,多对多需要创建一个中间表,中间表里有两个外键分别关联这两个表。
然后用 @@id 创建一个联合主键。
测试下:
npx prisma migrate dev --name ddd
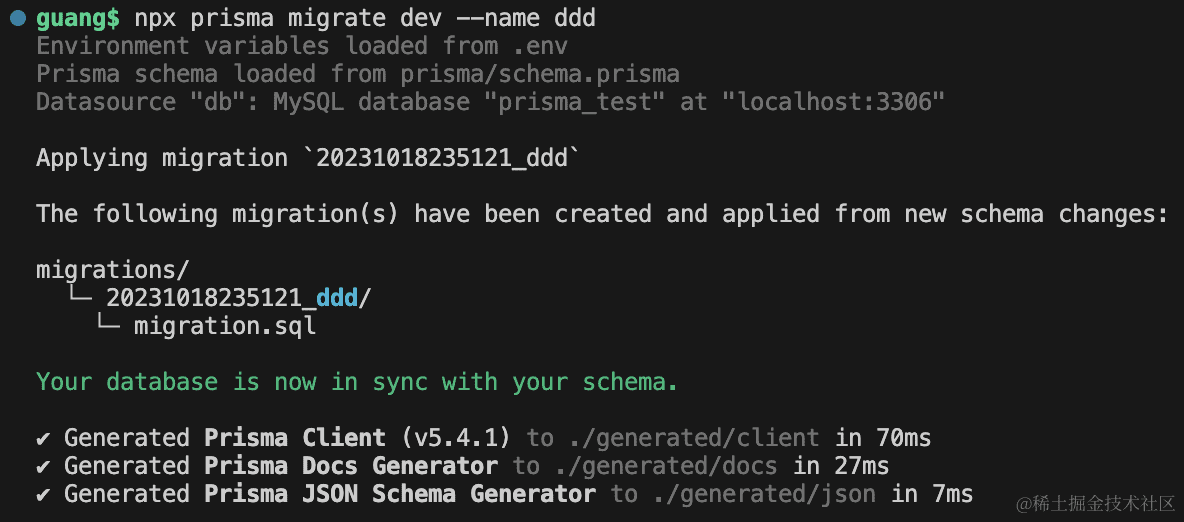
生成的 sql 如下:

中间表创建了 postId 和 tagId 的联合主键,并且创建了两个外键。
在 mysql 里可以看到这两个外键:
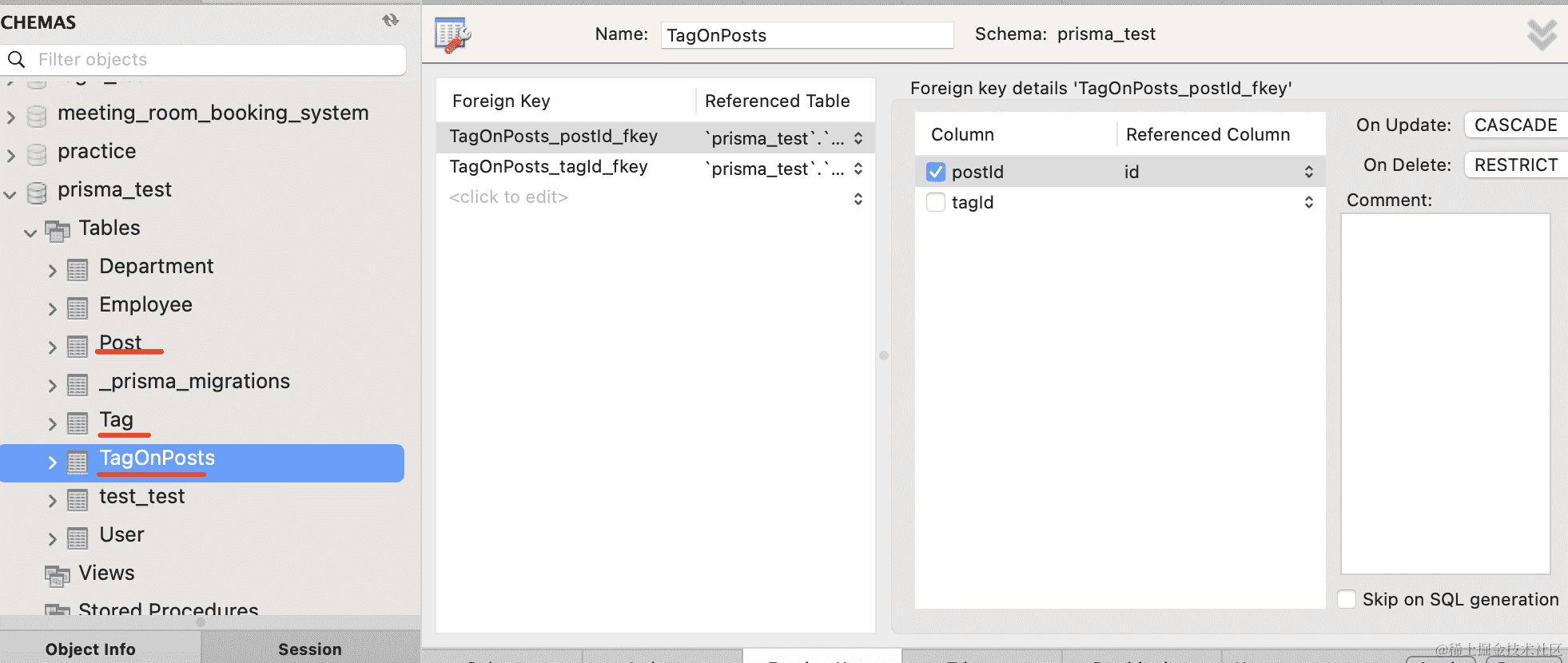
这就是一对多、多对多的映射方式。
至于一对一,那个就是在多的那一侧添加一个 unique 约束就好了:

这样就把一对多变成了一对一。
此外,还有一个 enum 的语法,就是可以指定某个字段只能取一些枚举值:
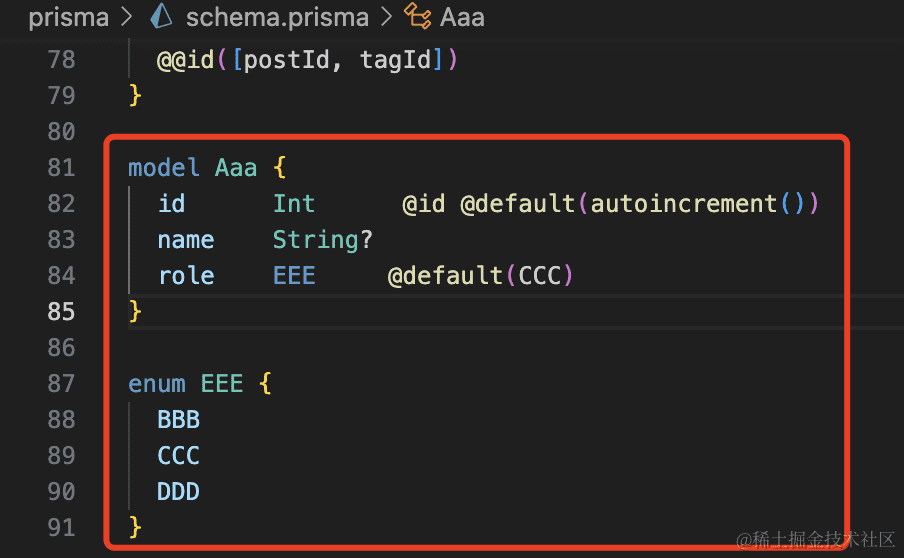
model Aaa {
id Int @id @default(autoincrement())
name String?
role EEE @default(CCC)
}
enum EEE {
BBB
CCC
DDD
}
创建迁移:
npx prisma migrate dev --name eee

生成的 sql 如下:
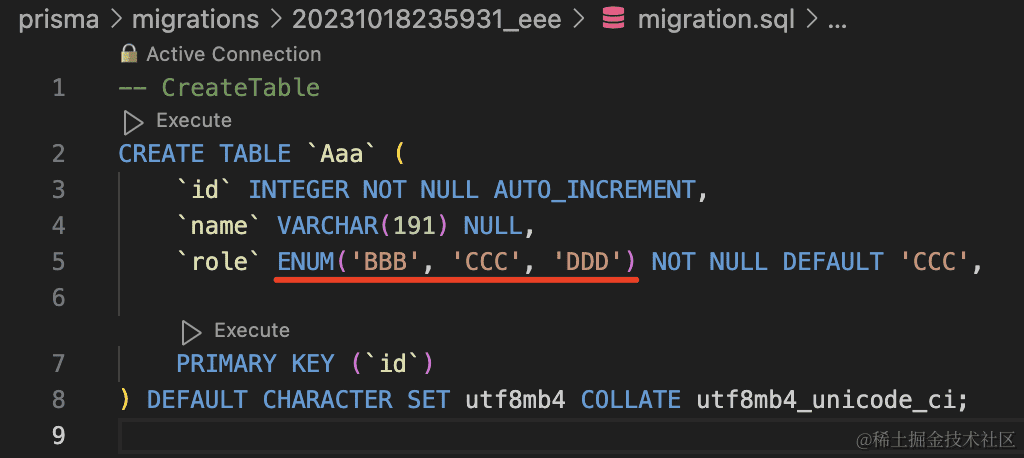
这个 enum 也是 sql 支持的语法(我们前面貌似没用过)。

这就是 prisma schema 的常用语法了,有一些不常用的没有列出来,大家遇去查schema 文档就好了。
最后,再看下生成的文档:
npx http-server ./generated/docs

每一个表的字段还有可用的 CRUD 方法都列出来了:

确实很方便。
案例代码在小册仓库
总结
这节我们学习了 prisma schema 的常用语法。
generator 部分可以指定多种生成器,比如生成 json 生成 docs 等,可以指定生成代码的位置。
datasource 是配置数据库的类型和连接 url 的。
model 部分定义和数据库表的对应关系:
- @id 定义主键
- @default 定义默认值
- @map 定义字段在数据库中的名字
- @db.xx 定义对应的具体类型
- @updatedAt 定义更新时间的列
- @unique 添加唯一约束
- @relation 定义外键引用
- @@map 定义表在数据库中的名字
- @@index 定义索引
- @@id 定义联合主键
此外,还可以通过 enum 来创建枚举类型。
这些就是常用的 schema 语法了。